
नोकरीच्या जाहिराती बघताना, interview preparation करताना किंवा data engineering बद्दलचे LinkedIn posts वाचताना एक शब्द वारंवार दिसतो — Databricks. नाव ओळखीचं वाटतं, पण प्रश्न तसाच राहतो: Databricks म्हणजे नेमकं काय? हा फक्त एक tool आहे, की Apache Spark चालवण्याचं ठिकाण, की अजून काही मोठी गोष्ट?
सोप्या भाषेत सांगायचं तर, Databricks हे data, analytics आणि AI साठीचं unified platform आहे. Databricks च्या अधिकृत documentation नुसार ते enterprise-grade data, analytics आणि AI solutions तयार, deploy आणि maintain करण्यासाठीचं open analytics platform आहे. म्हणजे data processing, notebooks, SQL analytics, collaboration, jobs, आणि AI workloads ही अनेक कामं एकाच ecosystem मध्ये हाताळता येतात.
हा लेख खास त्या वाचकांसाठी आहे ज्यांनी Databricks हे नाव ऐकलं आहे, पण अजून त्याची practical समज तयार झालेली नाही. विशेषतः fresher, working professional किंवा career-curious reader — ज्याला definition पाठ करायची नाही, तर concept समजून घ्यायचा आहे.
Databricks ची गरज का पडली?
प्रत्यक्ष project जगात एक common समस्या दिसते. Data एका storage मध्ये असतो, processing दुसऱ्या system मध्ये चालतं, BI reporting साठी वेगळं warehouse असतं, आणि machine learning साठी आणखी वेगळे tools लागतात. अशा setup मध्ये data ची copy वाढते, pipelines duplicate होतात, teams वेगळ्या systems मध्ये अडकतात, आणि “single source of truth” ही गोष्ट कागदावर जास्त दिसते, प्रत्यक्षात कमी.
Databricks च्या official documentation नुसार data lakehouse हे data lake आणि data warehouse यांचे फायदे एकत्र आणणारं data management system आहे. याचा उपयोग isolated systems टाळण्यासाठी, redundant cost कमी करण्यासाठी, आणि data freshness राखण्यासाठी होतो. यामुळे Databricks समजताना एक महत्त्वाची गोष्ट लक्षात ठेवावी लागते: ते फक्त code चालवण्याचं ठिकाण नाही. ते data platform अधिक साधं, एकत्रित आणि practical बनवण्याचा प्रयत्न आहे.
Databricks म्हणजे tool, की platform?
हा गोंधळ अगदी स्वाभाविक आहे. कारण अनेकांना Databricks चा पहिला परिचय Spark notebooks किंवा ETL jobs मधून होतो. त्यामुळे “हा Spark चा managed version असेल” असं वाटतं. पण Databricks त्यापेक्षा मोठी गोष्ट आहे.
Databricks हे platform आहे. ते cloud storage आणि cloud security सोबत integrate होतं, आणि compute infrastructure manage व deploy करण्यास मदत करतं. म्हणजे तुम्ही raw infrastructure कमी हाताळता आणि data workloads वर जास्त लक्ष देता. Databricks SQL, notebooks, pipelines, collaboration, governance आणि AI-related workflows हे सगळं broader platform experience चा भाग आहे.
म्हणून एका वाक्यात सांगायचं तर: Databricks हा फक्त software product नाही; तो modern data teams साठी काम करण्याचा एक पूर्ण environment आहे.
Databricks मध्ये नेमकं काय असतं?
Databricks समजून घेण्यासाठी त्याचे काही मुख्य building blocks पाहणे उपयोगाचं ठरतं. Feature list पाठ करणं इथे उद्देश नाही; तर platform कसं विचार करायचं हे समजून घेणं महत्त्वाचं आहे.
1.Workspace आणि Notebooks
Databricks workspace हे team चं working area असतं. इथे notebooks, shared development assets, jobs आणि इतर collaborative work हाताळता येतं. Notebooks मुळे Python, SQL आणि इतर supported languages वापरून data explore, transform आणि validate करणे सोपे होते. त्यामुळे experimentation आणि team collaboration या दोन्ही गोष्टी practical होतात.
2.Compute आणि Processing
तुम्ही लिहिलेला code execute होण्यासाठी compute लागतो. Databricks हा compute layer manage करण्यास मदत करतो, म्हणून distributed processing practical पद्धतीने वापरणं सोपं होतं. Data engineer च्या दृष्टीने ही महत्त्वाची गोष्ट आहे, कारण focus infrastructure वरून workload execution कडे सरकतो.
3.Databricks SQL
सगळं काम code-heavy असण्याची गरज नसते. अनेक organizations मध्ये analysts आणि BI teams साठी SQL हा primary interface असतो. Databricks SQL चा उद्देश lakehouse वर low-latency analytics, BI connectivity आणि high concurrency वापर शक्य करणे हा आहे. Power BI, Tableau, Looker सारख्या BI tools सोबत integration हा त्याचा practical फायदा आहे.
4.Delta Lake
Databricks ecosystem मधला एक खूप महत्त्वाचा भाग म्हणजे Delta Lake. Official docs नुसार Delta Lake हा Databricks lakehouse मधील tables चा foundational storage layer आहे. तो Parquet files वर transaction log देतो, ACID transactions, scalable metadata handling, batch आणि streaming या दोन्ही प्रकारच्या workloads साठी support देतो. Databricks वर default tables बहुतेक Delta format मध्येच असतात.
याचा अर्थ असा की Databricks मध्ये data फक्त store होत नाही; तो अधिक reliable, manageable आणि production-friendly पद्धतीने हाताळला जातो.
Databricks आणि Apache Spark यांचा संबंध काय?
हा interview मध्ये हमखास विचारला जाणारा प्रश्न आहे.
Apache Spark हा distributed processing engine आहे. मोठ्या प्रमाणातील data वर transformation, computation आणि parallel execution करण्याची ताकद Spark देतो. Databricks ची मुळे Spark ecosystem मध्ये खोलवर आहेत, आणि Spark-based workloads Databricks मध्ये naturally fit होतात. पण Databricks = Spark असं म्हणणं चुकीचं ठरेल.
यातील साधा फरक असा समजता येईल:
Spark = processing engine
Databricks = broader platform experience
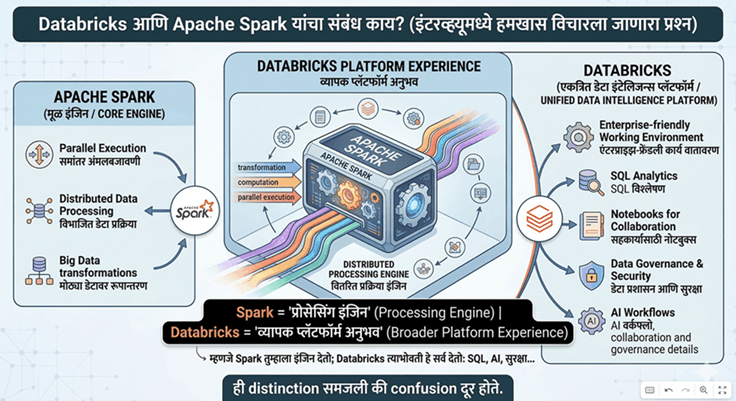
म्हणजे Spark तुम्हाला engine देतो; Databricks त्याभोवती enterprise-friendly working environment, SQL analytics, notebooks, governance, collaboration आणि AI workflows देतो. ही distinction समजली की Databricks बद्दलचा मोठा confusion कमी होतो.
Databricks कोणासाठी उपयोगी आहे?
Databricks चा उपयोग फक्त data engineers पुरता मर्यादित नाही. अधिकृत documentation आणि product positioning बघितली तर ते data, analytics आणि AI teams साठी तयार केलेलं platform आहे. मात्र practical जगात त्याची value वेगवेगळ्या लोकांसाठी थोडी वेगळी दिसते. Data engineer साठी Databricks म्हणजे scalable data processing, ETL pipelines, streaming आणि production workflows. Analyst साठी ते SQL queries, dashboards आणि BI connectivity. Data scientist किंवा ML engineer साठी shared data foundation आणि experiment-friendly environment. Platform team साठी governance, access patterns आणि centralized control.
म्हणजे Databricks शिकताना syntax पेक्षा role clarity जास्त महत्त्वाची ठरते. तुम्ही platform कशासाठी वापरणार आहात — ETL, analytics, reporting, ML की governance — यावर तुमची learning path बदलते.
Databricks चा practical फायदा नेमका कुठे दिसतो?
“हे सगळं theoretical ठीक आहे, पण actual कामात फायदा काय?” हा योग्य प्रश्न आहे. समजा एका retail company कडे website clicks, app logs, customer orders, product catalog आणि sales transactions असा data वेगवेगळ्या स्वरूपात cloud storage मध्ये येतो. पारंपरिक setup मध्ये raw data एका ठिकाणी, cleaned reporting tables दुसऱ्या system मध्ये, आणि ML टीमसाठी copies तिसरीकडे तयार होऊ शकतात.
Databricks चा lakehouse approach अशा fragmentation ला कमी करण्याचा प्रयत्न करतो. Data ingest करून transform करता येतो, curated tables तयार करता येतात, analysts साठी SQL access देता येतो, dashboards चालवता येतात, आणि त्याच data foundation वर AI किंवा ML workflows सुद्धा build करता येतात. अधिकृत docs या unified model मुळे isolated systems, redundant costs आणि stale data यांसारख्या समस्यांवर उपाय शोधण्यावर भर देतात. याचा मोठा फायदा असा की team-to-team friction कमी होऊ शकतो. Data वेगवेगळ्या silos मध्ये फिरवण्याऐवजी shared foundation वर काम करता येतं. आणि हेच Databricks चं practical appeal आहे.
पण प्रत्येक team साठी Databricks योग्यच असतं का?
Databricks powerful आहे, पण याचा अर्थ तो प्रत्येक organization साठी automatic best choice आहे असं नाही. त्यात learning curve असू शकतो. Cloud compute चा वापर समजून न घेतल्यास cost control हा मुद्दा महत्त्वाचा ठरू शकतो. आणि जर एखाद्या team ची गरज फक्त simple reporting किंवा limited SQL warehousing इतकीच असेल, तर इतर platforms काही वेळा अधिक suitable वाटू शकतात.
आजच्या data platform जगात Snowflake, Azure Synapse आणि इतर पर्यायही उपलब्ध आहेत. Databricks विशेषतः data engineering, Spark-oriented processing, lakehouse architecture, analytics आणि AI workloads एकत्र हाताळण्याच्या क्षमतेमुळे वेगळं भासतो. त्यामुळे “कोणता platform best?” यापेक्षा “आपल्या use case साठी कोणता platform fit आहे?” हा प्रश्न जास्त प्रामाणिक आहे.
नवशिक्यांनी Databricks बद्दल आधी काय समजून घ्यावं?
Databricks शिकायला सुरुवात करताना सगळ्या features मध्ये हरवण्याची गरज नाही. आधी काही foundational गोष्टी स्पष्ट झाल्या तरी भक्कम पाया तयार होतो. पहिली गोष्ट म्हणजे Databricks हे single-purpose tool नाही; ते unified platform आहे. दुसरी गोष्ट म्हणजे lakehouse हा फक्त marketing शब्द नाही; तो data lake आणि data warehouse यांच्यातल्या practical gap ला उत्तर देण्याचा प्रयत्न आहे. तिसरी गोष्ट म्हणजे Spark समजणं उपयोगाचं आहे, पण Databricks शिकणं म्हणजे फक्त Spark syntax शिकणं नाही. आणि चौथी गोष्ट म्हणजे production data platform मध्ये reliability, governance, collaboration आणि cost awareness या गोष्टी तितक्याच महत्त्वाच्या असतात जितक्या code execution. म्हणून शिकताना feature-by-feature approach पेक्षा use-case approach अधिक उपयोगी पडतो.
म्हणून “Databricks म्हणजे काय?” या प्रश्नाचं साधं उत्तर असा देता येईल : ते data, analytics आणि AI साठीचं unified platform आहे, जे lakehouse architecture च्या मदतीने वेगवेगळे workloads एकत्र आणण्याचा प्रयत्न करतं. पण खरी गोष्ट definition पेक्षा थोडी मोठी आहे. Databricks समजण्याचा मुद्दा फक्त tool ओळखण्याचा नाही; तर modern data work का complex झालं आहे, teams का तुटतात, data copies का वाढतात, आणि reliability इतकी महत्त्वाची का ठरते हे समजण्याचा आहे.
Tools येतात आणि जातात. पण data reliable, usable आणि trustworthy बनवण्याची गरज बदलत नाही. Databricks शिकताना ही गोष्ट लक्षात ठेवली, तर उरलेली features आणि terms हळूहळू स्वतःच्या जागेवर बसू लागतात.
FAQ
1) Databricks आणि Spark एकच आहेत का?
नाही. Spark हा distributed processing engine आहे, तर Databricks हे broader platform आहे ज्यात notebooks, compute, SQL, collaboration आणि AI-related capabilities येतात.
2) Databricks शिकण्यासाठी Python लागते का?
Python उपयोगी ठरते, पण फक्त Python पुरेसं नाही. SQL, data concepts, ETL thinking आणि cloud basics यांची समजही महत्त्वाची असते, विशेषतः practical project work साठी. Databricks SQL सुद्धा platform चा महत्त्वाचा भाग आहे.
3) Delta Lake म्हणजे काय?
Delta Lake हा Databricks मधील storage layer आहे जो Parquet files वर transaction log, ACID transactions, scalable metadata handling आणि batch-streaming support देतो. Databricks मध्ये तो tables साठी foundational layer म्हणून वापरला जातो.
4) Databricks फक्त data engineers साठीच आहे का?
नाही. Databricks data engineering, analytics, BI आणि AI workloads साठी वापरला जातो. त्यामुळे analysts, engineers, data scientists आणि platform teams — सगळ्यांसाठी त्याची उपयोगिता वेगवेगळ्या प्रकारे दिसू शकते.