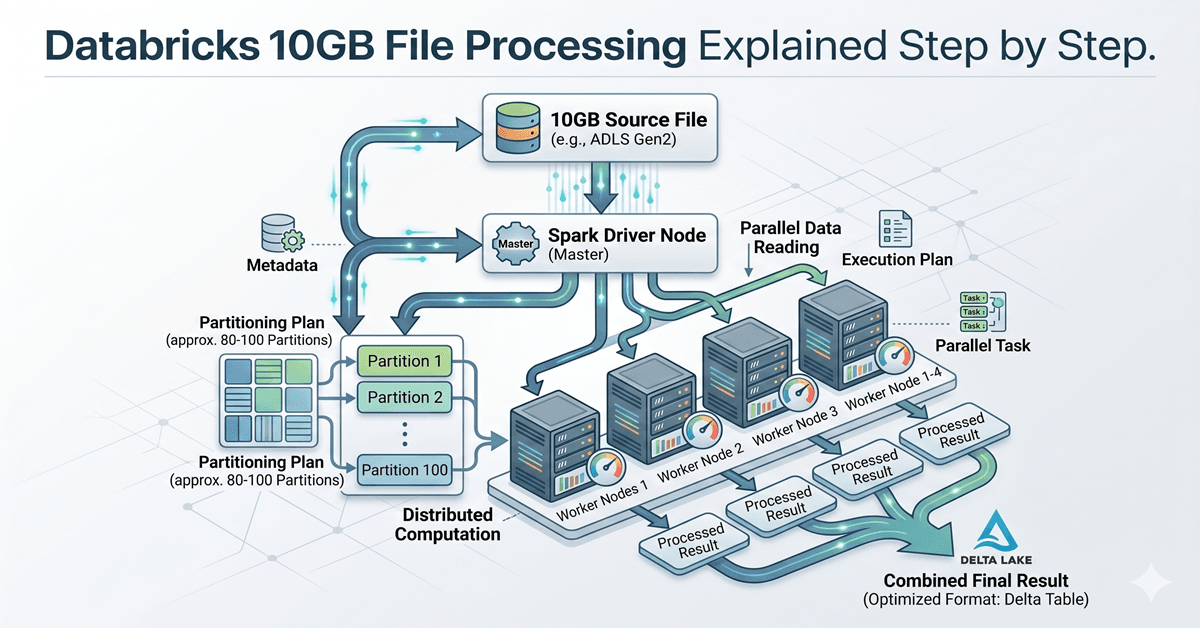
Databricks 10GB File Processing Explained Step by Step.
Databricks 10GB file processing sounds complex at first, especially when you imagine loading a massive file into memory. But Databricks processes large files differently by splitting data into partitions and distributing work across clusters. Understanding Databricks 10GB file processing helps beginners understand how Spark handles scale efficiently.
This creates a natural assumption:
“If a file is 10GB, processing it must require a very powerful machine.”
That assumption makes sense in traditional computing.But Databricks works differently.
In Databricks, a 10GB file is not treated as one heavy object that must be loaded into memory at once. Instead, the system breaks the file into smaller pieces, distributes the workload across multiple machines, and processes everything in parallel.
This article is written for beginners, career switchers, and people entering the data engineering or analytics world who want to understand how Databricks thinks about large files — not just memorize definitions.
Why a 10GB File Feels Big on a Laptop but Normal in Databricks
When you work on a local computer, most operations depend on a single machine.
Your laptop has:
- One processor
- Limited memory
- Limited storage bandwidth
- Limited ability to process multiple heavy operations simultaneously
If you try to load a 10GB CSV file locally, the system may attempt to read a large portion of that data into memory.This becomes difficult because traditional applications are designed for single-machine execution.Databricks follows a completely different philosophy.Instead of depending on one machine, it uses distributed computing. Distributed computing means multiple machines share work.
This difference is the reason Databricks can comfortably process files that would crash a normal desktop environment.
First, Where Does the File Actually Live?
A common beginner misconception is that Databricks stores files internally. In reality, Databricks usually does not act as long-term storage. A 10GB file typically sits in cloud storage such as:
- Amazon S3
- Azure Data Lake Storage
- Google Cloud Storage
Databricks connects to these storage systems and processes data from there. This separation is important. Storage and compute are treated independently. Cloud storage keeps the file safely stored. Databricks provides the computing power needed to read and process it. This separation creates flexibility. You can keep thousands of files stored cheaply while scaling processing power only when required.
For example, a company may store several years of customer transactions in cloud storage but only spin up a Databricks cluster when analysis is needed.
Step 1: Databricks Does Not Read the Entire File at Once
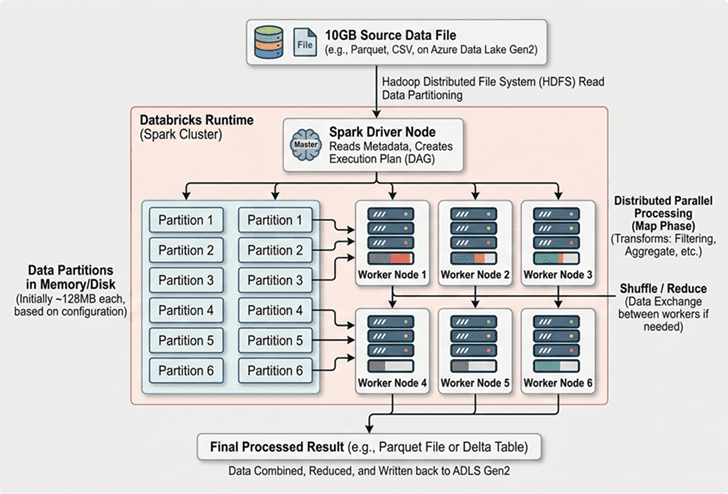
When Databricks reads a file, Spark does not immediately load the full 10GB into memory. Instead, Spark creates smaller logical pieces called partitions. A partition is simply a chunk of data that can be processed independently. Think of a large book. If one person reads all 500 pages, the process takes longer. But if ten people each read 50 pages simultaneously, the work finishes faster. That is exactly how Spark approaches large data. The file is divided into manageable sections so multiple workers can process them simultaneously.
This is one of the core ideas behind distributed systems.
Databricks 10GB File Processing Through Partitions
This is where many beginner articles stay vague.
Let’s make it practical.
Spark typically works with partition sizes around 128MB by default. This is not a strict rule, but it is commonly used as a baseline. If you divide 10GB by 128MB, the file may result in roughly 80 partitions. Here is a simplified calculation:
10GB = approximately 10,240MB
10,240MB / 128MB = around 80 partitions
This means Spark may divide the file into around 80 manageable chunks. Each partition becomes an independent task. That matters because tasks can run in parallel. Instead of processing 10GB sequentially, Spark processes many partitions at the same time.
The exact number of partitions may change depending on:
- File format
- Compression
- Cluster configuration
- Spark settings
- Data source
But the important idea remains the same:
Databricks works by splitting work, not by scaling one machine endlessly.
Step 2: Databricks 10GB File Processing Inside Clusters
Databricks runs workloads using clusters. A cluster is a group of machines working together.
A simple cluster may contain:
- 1 Driver Node
- 4 Worker Nodes
The Driver Node acts like a coordinator.
It decides:
- What work exists
- Which tasks must run
- Which worker gets which partition
The Worker Nodes perform actual processing. Each worker receives a portion of the data.
For example:
- Worker 1 processes partitions 1–20
- Worker 2 processes partitions 21–40
- Worker 3 processes partitions 41–60
- Worker 4 processes partitions 61–80
This division allows processing to happen simultaneously. Instead of waiting for one machine to finish everything, multiple workers contribute. This parallel execution dramatically reduces runtime.
Visual Understanding — How a 10GB File Gets Processed
Step 3: Spark Does Not Execute Immediately
One of the most misunderstood concepts in Spark is lazy execution. When beginners write code, they often assume Spark immediately runs every line. That is not how Spark behaves.
For example:
sales_df = spark.read.csv("sales.csv")
filtered_df = sales_df.filter("country = 'India'")
city_df = filtered_df.groupBy("city").count()Many people assume Spark processes the data after every line. But Spark usually waits. Instead of running instantly, Spark builds a logical plan.
It studies:
- Which file must be read
- Which filters exist
- Which grouping operation is needed
- Which transformations can be optimized
Nothing actually executes until an action happens.
For example:
city_df.show()This .show() command triggers execution.
At that moment, Spark begins reading partitions and distributing work. This behavior is called lazy execution. Spark waits until it truly needs a result. This improves performance because unnecessary work gets avoided.
Why Lazy Execution Matters for Large Files
Without lazy execution, Spark might repeatedly scan the same 10GB file after every command. That would waste processing time. Instead, Spark creates an optimized plan before touching data.
This means Spark can:
- Combine operations
- Reduce repeated scanning
- Push filters earlier
- Minimize memory usage
For large datasets, this optimization becomes extremely valuable. Even a small reduction in unnecessary processing can save minutes or hours in enterprise workloads.
Step 4: Memory Does Not Need to Hold Everything
One major misconception is that Databricks must load the entire file into RAM. This is not true. Spark processes data in chunks. Each worker loads only relevant partitions. If memory becomes limited, Spark can temporarily spill intermediate data to disk. This prevents system crashes. A local laptop often fails because it tries to load too much at once. Databricks avoids this by distributing memory usage across machines.
This architecture makes large-file processing more reliable.
Why File Format Changes Everything
A 10GB CSV file and a 10GB Parquet file are not equal. This is an important concept many beginners overlook. CSV is a text-based format. Spark must scan the file row by row. Parquet works differently. Parquet stores data in columns. That means Spark can read only required columns instead of scanning everything.
For example:
Imagine a sales table with 30 columns.
If you only need:
- customer_id
- purchase_amount
- city
Spark may read only those columns from a Parquet file. With CSV, Spark still scans the entire file. This is why Parquet usually performs better. Databricks strongly encourages columnar storage formats for large-scale workloads.
Why Databricks Often Converts Data into Delta Tables
Raw files are useful for ingestion. But enterprise systems rarely keep querying large CSV files repeatedly. Databricks often converts raw files into Delta format. Delta Lake improves performance because it adds structure and metadata.
Delta tables support:
- Faster reads
- ACID reliability
- Incremental updates
- Schema enforcement
- Better optimization
For example, if a company processes daily sales files, Databricks may convert each incoming file into a Delta table. Over time, querying becomes faster because Spark understands the table structure. This reduces repeated scanning and improves reliability.
A Real Enterprise Example
Imagine an e-commerce company uploading a 10GB daily order file.
The file contains:
- Customer orders
- Product details
- Payment information
- Delivery timestamps
- City-level sales records
If processed traditionally, one server would attempt to read everything sequentially. Databricks works differently. The file gets partitioned. Workers process separate chunks. Spark applies filters. Aggregations happen in parallel.
The final result may answer questions such as:
- Which cities generated the highest sales?
- Which products performed best?
- Which payment methods failed most frequently?
Even though the source file is 10GB, the user experiences the result as one query. That simplicity hides substantial complexity underneath.
Common Beginner Mistakes
Many beginners entering Databricks make similar assumptions. One common misunderstanding is believing cluster size alone solves performance issues. More machines help, but poor partitioning still causes bottlenecks. Another mistake is assuming CSV works fine for everything. CSV may work initially, but performance often improves afte
A 10GB file may feel large on a personal computer, but Databricks processes it differently by using distributed computing. Instead of loading the entire file into memory, Spark divides it into partitions and distributes those partitions across multiple worker nodes inside a cluster. This parallel processing reduces execution time and avoids memory limitations. Understanding how Databricks processes large files is less about memorizing technical terms and more about understanding the architecture behind modern data systems. Concepts like partitioning, lazy execution, cluster coordination, and optimized file formats help explain why platforms like Databricks scale efficiently.
For beginners, the key takeaway is simple: Databricks does not make one machine stronger — it makes many machines work together intelligently. Databricks 10GB file processing becomes easier to understand once you see how Spark partitions data across clusters.
Yeah I agree, the platform interface is way cleaner than most competitors out there and their support team actually responds in like 5 minutes. babu88 login
dude check this out 7Signs is actually pretty solid, like the whole thing loads fast and they got decent promos going on. give it a try man 7signs